
Introduction: Why Traditional Machine Learning Batch Processing Is No Longer Enough
For years, machine learning lived comfortably in batch pipelines. Predictions were generated overnight. Models were updated weekly. Latency didn’t matter.
That world is gone.
In 2026, ML systems are expected to respond in milliseconds, adapt continuously, and operate reliably at scale. This demand has triggered a major evolution in real-time Machine Learning tooling and it’s reshaping how systems are designed.
Why Real-Time ML Is So Hard
Real-time ML isn’t just “faster batch processing.” It introduces entirely new challenges:
- Low-latency inference
- Streaming data ingestion
- Model drift detection
- Continuous monitoring
- High availability under load
Most early ML stacks were never designed for this.
What’s New in Real-Time ML Tooling
Recent tooling advances focus on end-to-end real-time Machine Learning systems, not isolated components.
1. Streaming-First Data Pipelines
Modern ML platforms now support:
- Native event streams
- Online feature stores
- Low-latency feature computation
This allows models to react to live user behavior instead of stale snapshots.
2. Real-Time Inference Engines
Inference tooling has improved dramatically:
- Sub-10ms response times
- Auto-scaling under burst traffic
- Hardware-aware optimization
This makes ML viable for use cases like fraud detection, recommendations, pricing, and personalization.
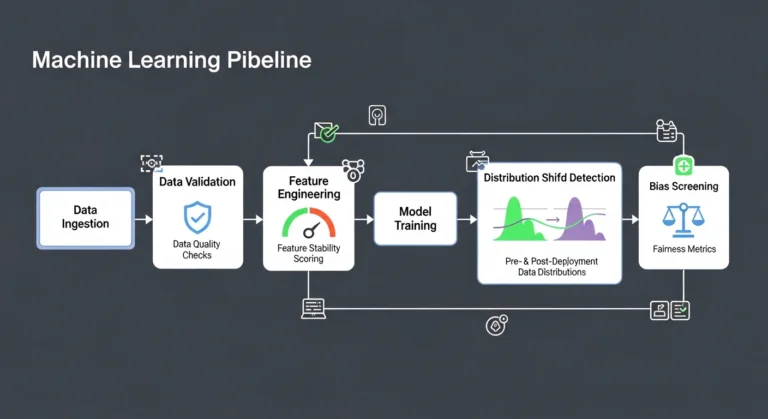
3. ML Observability and Monitoring
One of the biggest breakthroughs is ML observability:
- Drift detection
- Feature distribution monitoring
- Prediction confidence tracking
- Performance regression alerts
Teams can now see when models degrade before customers notice.
4. Continuous Deployment for Models
Real-time ML tooling supports:
- Safe model rollouts
- Shadow deployments
- Canary testing
- Automated rollback
This brings DevOps discipline into ML workflows often called MLOps 2.0.
Why This Matters for Revenue
Real-time ML directly impacts business outcomes:
- Fraud prevention reduces losses instantly
- Recommendations increase conversion rates
- Dynamic pricing improves margins
- Personalization boosts retention
Latency is no longer technical it’s financial.
Architecture Shift: From Pipelines to Systems
Successful real-time ML requires a mindset shift:
- From training pipelines → always-on systems
- From offline evaluation → continuous validation
- From static models → adaptive services
This demands closer collaboration between ML, backend, and infrastructure teams.
Common Mistakes Teams Still Make
Despite better tooling, many teams fail because they:
- Ignore data freshness
- Underinvest in monitoring
- Treat models as static assets
- Optimize accuracy while ignoring latency
Real-time ML punishes shortcuts.
What Teams Should Do in 2026
To succeed with real-time ML:
- Design for observability first
- Invest in feature stores and streaming data
- Treat models as production services
- Align ML and engineering teams
The tools exist. The discipline must follow.
Final Thoughts
Real-time ML is no longer a competitive advantage it’s becoming a baseline expectation. Organizations that master it will deliver smarter, faster, and more responsive products. Those that don’t will feel slow, irrelevant, and expensive.
If you’re building real-time systems and need help with architecture, tooling, or deployment, explore machine learning consulting at Contact Us
Similar Posts

Marketing
9 Proven Benefits of AI Search Integration for Better Content Discovery
AI search integration is transforming how content is discovered, summarized, and ranked in modern search engines. In 2026,…
AI
Data Quality Scoring Is Becoming Standard, Not Optional
In the early days of machine learning and analytics, teams often rushed toward model training with one assumption:…